Notre représentation du domaine ou ontologie se compose d’une partie
arborescence conceptuelle, qui sert simultanément à recenser les concepts du
domaine et à les classer au sein d’une hiérarchie de subsomption, et d’une
partie plus conséquemment sémantique modélisant les relations entre concepts
relevées dans les documents traités.
La
partie
arborescence conceptuelle rassemble les 1500 à 2500
syntagmes extraits du domaine au sein d’un ensemble
d’arborescences composées au maximum d’environ 300
syntagmes. Chacune de ces arborescences concerne plus spécifiquement un
sous-domaine géotechnique (matériels, géologie, stabilité des sols, …).
L’objectif de cette séparation est double :
* Autoriser
les variations éventuelles dans les hiérarchies dues aux hétérogénéités
conceptuelles entre spécialités, d’une part (le « sol » d’un géologue
consiste essentiellement en roche-mère et est situé à plusieurs mètres sous la
surface, tandis que le « sol » d’un expert en stabilité des pentes
consiste essentiellement en couches superficielles détritiques et excède
rarement les 30 mètres de profondeur sous la surface)
* Fragmenter
l’ensemble de concepts en sous-ensembles les rend manipulables par les utilisateurs. Non
qu’un système informatique ne puisse stocker des dizaines de milliers de
concepts, mais il paraît inenvisageable à un utilisateur de le faire et de les
manipuler. Donc, en-dehors de tout modèle formel qui permette de classer
automatiquement des nouveaux concepts, la maintenance et l’augmentation de
telles arborescences est envisageable dans le cadre d’une utilisation orientée
métier avec l’aide de graphes heuristiques (Jésus M., 2009)
A l’heure
actuelle, chaque arborescence locale (nommée « couche métier ») fait
partie d’un ensemble rassemblant une vingtaine de spécialités du domaine, et la
possibilité d’autoriser de nouvelles couches plus personnelles et orientées
vers des pratiques particulières et des concepts familiers est opérationnelle.
Dans la
mesure où les syntagmes sont nominaux et désignent des concepts du domaine
partagés par les différentes spécialités, l’alignement des couches métier pour
former une arborescence globale destinée à faciliter la recherche d’information
peut s’appuyer sur les nombreux concepts communs entre couches (environ 200
avec notre corpus actuel). Ce sont ces syntagmes qui permettent l’alignement
des « petits réseaux syntaxiques ou sémantiques » correspondant aux
couches métiers pour réaliser, dans la machine, l’ontologie hybride.(Tallens,
Boulanger, 2009) (Ziani, 2012).
Il a été
mentionné ci-dessus que les concepts classés dans ces arborescences ne sont pas
formellement modélisés. Habituellement, un concept est formellement défini
comme une catégorie aristotélicienne implémentée dans un modèle ou un autre,
c’est-à-dire par un ensemble de propriétés considérées collectivement comme
essentielles[1]
au concept. Cette modélisation du concept a fait ses preuves pour le calcul
automatique, mais l’on sait depuis les travaux de Wittgenstein que l’esprit
humain ne fonctionne pas de cette manière, et les experts géotechniciens jugent
très artificiel le fait de tenter de définir ainsi les concepts qu’ils
emploient. (Wittgenstein, 1993). Pratiquement, notre approche repose sur le
fait que la représentation des connaissances issues de textes s’apparente plus
à représenter une connaissance communicationnelle que langagière, et s’inscrit
donc dans une semiosis secondaire dynamique[2],
réactualisée au fil du discours. (Chingareva-Slavine, 2003).
C’est
pourquoi, plus que la représentation formelle d’un concept, on s’attache à
représenter les relations entre concepts (tels que désignés par des syntagmes
nominaux) dans un fragment de texte[3].
Le formalisme utilisé pour cette représentation dérive de la DRT[4] et
introduit un ensemble de relations entre concepts à un niveau local. (Kamp et
Reyle, 1993). Il s’agit du granule de connaissance, décrit plus avant dans
d’autres documents et rappelé ci-après. (Faure, 2007).
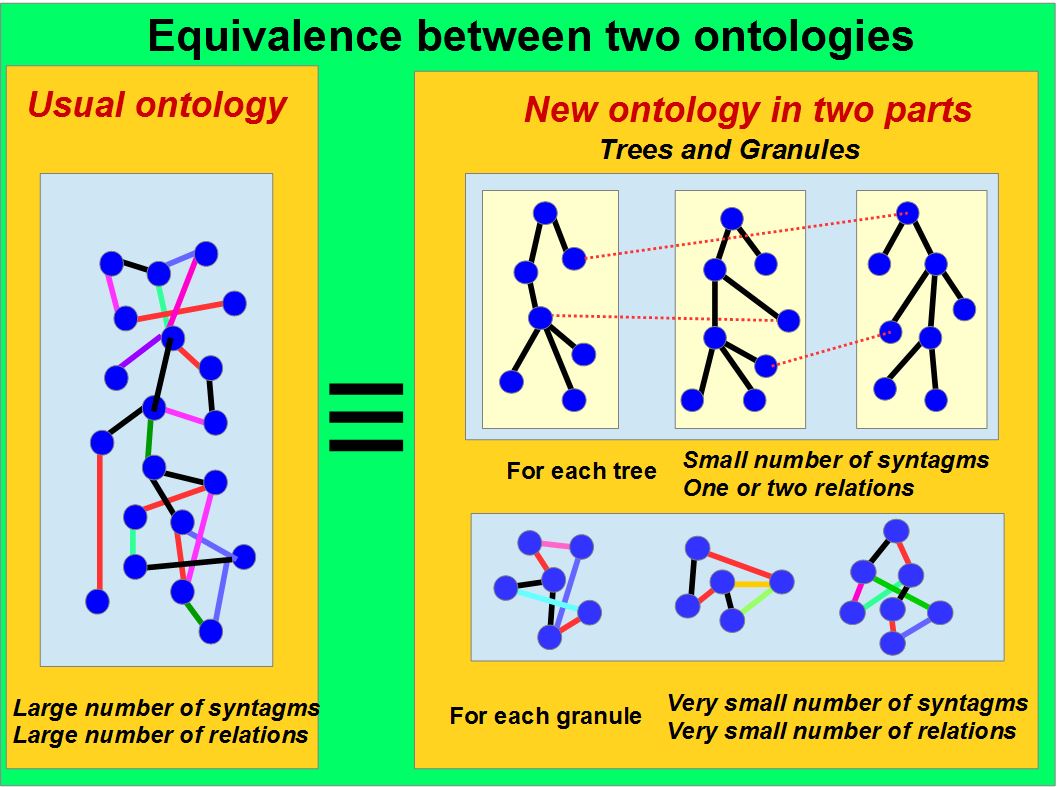
Le schéma suivant représente l’équivalence entre une ontologie classique comme DOLCE (Dolce, 2004) et la structure utilisée dans MKD. Les arborescences « couches métiers » définissent le lexique du domaine et les « granules » sont des ontologies locales définies par le « fragment de texte » qui s’apparente à une règle de production. L’automatisation de l’extraction des fragments de texte et de leur transformation en granule est un des enjeux du projet. Près de 1000 fragments de texte ont été identifiés par lecture attentive des textes et un premier automate réussit la transformation ces fragments de texte en granule, à plus de 50) %. (Faure, 2008)
N1, N2 et M sont des grands nombres, plusieurs milliers.
L’ontologie de MKD est équivalente à
une ontologie classique
[1]
Par opposition aux propriétés accidentelles
[2]
« Par semiosis, on entend habituellement le processus de dénotation des
objets par des signes. Donc, l’outil principal de la sémiosis est le signe
grâce auquel la semiosis se réalise : dans la langue (semiosis primaire
stable) et dans le discours (semiosis secondaire dynamique) ».
(Chingareva-Slavine, 2003).
[3]
Il s’agit d’un fragment thématique ; la phrase n’étant pas un ensemble
sémantique toujours cohérent, cet ensemble est plutôt défini comme un
paragraphe composite. L’utilisation d’approches comme le text-tiling (Hearst,
1997) est à l’étude pour générer automatiquement ces fragments de textes.
[4] Discourse Representation Theory (Kamp et Reyle, 1993).