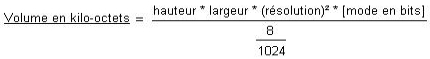Nous ferons ici une présentation de "l'image
numérique" dans ses grandes lignes.
-
Qu'est ce qu'une image
numérique?
Une image, du latin
imago, désigne la représentation 2D (notamment visuelle)
d'un objet, d'une chose ou d'un environnement 3D par
différents moyens ou supports : dessin, image
numérique, peinture, photographie, etc. ...
L'image numérique, est une image qui est
décrite dans un langage informatique ce qui lui permet
d'être enregistrée sur différents supports
magnétiques (disque rigide, disquette...) ou optiques (CD, par
exemple);
En infographie, on distingue deux grandes
familles d'images numériques :
- les
images vectorielles
- les
images matricielles.
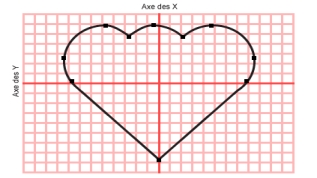
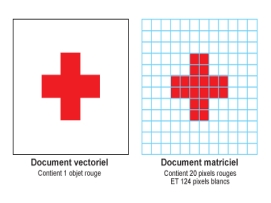
Les images vectorielles sont des
représentations d'entités géométriques telles
qu'un cercle, un rectangle ou un segment. Ceux-ci sont
représentés par des formules mathématiques (un
rectangle est défini par deux points, un cercle par un centre
et un rayon, une courbe par plusieurs points et une
équation).
Les formes plus complexes sont subdivisées
en segments de droite ou de courbe. Ils sont reliés entre eux
par des points d'ancrage dont la position relative est
enregistrée sous forme de coordonnées (X,Y).
Ainsi il est possible de lui appliquer facilement
des transformations géométriques (zoom, étirement,
...) sans perte d'information et de définir une image avec
très peu d'information, ce qui rend les fichiers très peu
volumineux.
Cependant, une image vectorielle permet
uniquement de représenter des formes simples. S'il est vrai
qu'une superposition de divers éléments simples peut
donner des résultats très impressionnants, toute image ne
peut pas être rendue vectoriellement, c'est notamment le cas
des photos réalistes.
Ces images sont donc essentiellement
utilisées pour réaliser des schémas ou des plans.
Les logiciels de dessin industriel fonctionnent suivant ce principe
; les principaux logiciels de traitement de texte ou de PAO
(publication assistée par ordinateur) proposent également
de tels outils.
Les images matricielles sont composées de
petits carreaux colorés (y compris le blanc, le noir et les
différentes nuances de gris), appelés pixels.
Définition du pixel :
selon la définition du Conseil international
de la langue française, pixel est la forme abrégée
de l’expression anglo- américaine « picture element
». C’est l’élément le plus petit
d’une surface de détection (le capteur de
l’appareil photo), d’une image échantillonnée
ou d’une surface de visualisation (par exemple un
écran), auquel puisse être affecté individuellement
des caractéristiques visuelles.
Pour décrire une image matricielle, il faut
compiler les informations suivantes :
-
la taille des pixels, qui est indiquée par
la résolution de l'image;
-
la valeur de couleur de chacun des pixels
-
leur position dans l'image.
Les images vues sur un écran de
télévision ou une photographie sont des images
matricielles.
On obtient également des images matricielles
à l'aide d'un appareil photo numérique, d'une caméra
vidéo numérique ou d'un scanner:
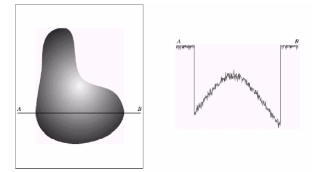
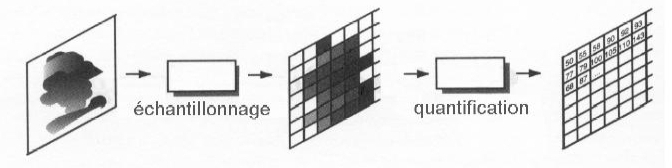
L'acquisition se fait par un capteur, une
photodiode par exemple :
l'énergie incidente est convertie en signal
électrique, il est proportionnel à l'intensité
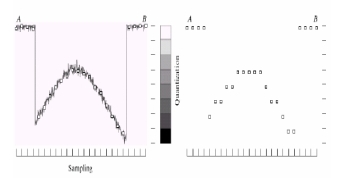
lumineuse ; pour numériser l'image il faut échantillonner
le signal puis le quantifier comme le montre l'exemple
suivant:
A la fin on obtiendra un tableau de valeur,
appelé matrice, où chaque valeur de chaque case, les
pixels, est codée dans un intervalle de tons ou de couleurs
défini par le capteur. L'échantillonnage est limité
par la capacité du capteur, donc le nombre de pixels
disponible.
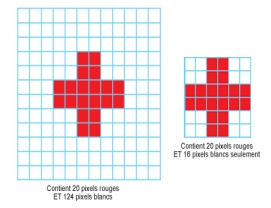
Plus la densité des pixels est
élevée, plus le nombre d'informations est grand et plus
la résolution de l'image est élevée.
La résolution joue un rôle primordial
en regard de la qualité des images : en général,
plus la résolution est élevée, plus nettes et
détaillées apparaissent les images comme nous le
montrerons plus tard.
-
Les dimensions et la
résolution
Un document matriciel se caractérise par sa
dimension, sa résolution et son codage ou mode. Ces
caractéristiques ont à leur tour, un effet direct sur le
volume du document.
La matrice de pixels s'étend à
l'ensemble de la surface du document, qu'il y ait ou non une
représentation graphique sur le document. Un document
vectoriel dans lequel il n'y a rien est un document vide. Par
contre, un document matriciel dans lequel il n'y a aucune
représentation graphique est quand même composé
d'une matrice de pixels blancs qui occupe une certaine
quantité de mémoire.
La résolution est l'expression de la taille
des pixels. Elle s'exprime en PIXELS PAR POUCE (PPI). Plus la
valeur de la résolution est élevée, plus les pixels
sont petits et plus il en faut pour combler la matrice d'un
document de même dimension.
Exemple:
18 pixels par pouce soit environ 7 pixels par cm
dans ce cas on observe l'effet de pixelisation :
72 pixels par pouce soit environ 30 pixels par
cm. Cette dernière résolution correspond
approximativement à celle d'un écran d'ordinateur, elle
est donc idéale pour visualiser une image sur l'écran
:
-
-
Codage d'une image en noir et blanc
Pour ce type de codage, chaque pixel est soit
noir, soit blanc. Il faut un bit pour coder un pixel (0 pour noir,
1 pour blanc). L'image de 10000 pixels codée occupe donc 10000
bits en mémoire.
Ce type de codage peut convenir pour un plan ou
un texte mais on voit ses limites lorsqu'il s'agit d'une
photographie.
-
Codage d'une image en niveaux de gris
Si on code chaque pixel sur 2 bits on aura 4
possibilités (noir, gris foncé, gris clair, blanc).
L'image codée sera très peu nuancée.
En général on code chaque pixel sur 8
bits = 1 octet. On a alors 256 possibilités (on dit 256
niveaux de gris). L'image de 10 000 pixels codée occupe alors
10 000 octets en mémoire.
-
Codage d'une image en couleurs 24
bits
Il existe plusieurs modes de codage de la
couleur. Le plus utilisé est le codage Rouge, Vert, Bleu (RVB
ou RGB en anglais). Chaque couleur est codée sur 1 octet,
chaque pixel sur 3 octets c'est à dire 24 bits : le rouge de 0
à 255 , le vert de 0 à 255, le Bleu de 0 à
255.
Le principe repose sur la synthèse additive
des couleurs : on peut obtenir une couleur quelconque par addition
de ces 3 couleurs primaires en proportions convenables.
On obtient ainsi 256 x 256 x 256 = 16777216 (plus
de 16 millions de couleurs différentes).
-
Codage d'une image en couleurs 8
bits
Dans ce cas on attache une palette de 256
couleurs à l'image.
Ces 256 couleurs sont choisies parmi les 16
millions de couleurs de la palette RVB, ainsi pour chaque image, le
programme recherche les 256 couleurs les plus pertinentes.
Chaque code (de 0 à 255) désigne une
couleur, l'image occupe donc 3 fois moins de place en mémoire
qu'avec un codage 24 bits. L'image est moins
nuancée : sa qualité est bonne mais moindre.
Le choix de la palette de couleur peut être
défini par l'utilisateur (cas des fausses couleurs) ou
optimisé par calcul.
On peut maintenant obtenir le volume d'une image
quand on connait ces 3 critères par la formule suivante:
Il existe plusieurs types de format comme le
format GIF, TIFF ou PNG ..... Ici on s'interessera plutôt aux
deux formats que nous utiliserons et qui sont les deux
principaux:
Le format BMP est le format standard de la prise
numérique d'une image, la taille des images dans ce format est
très importante (selon l'image jusqu'à 50 fois plus
grande qu'une image jpg) mais sa qualité est meilleure.
- Le JPEG
(Joint Photo Expert Group):
Le format JPEG est un format de compression
d'image réglable, avec perte de qualité. Plus la
compression est importante, plus l'image est
dégradée.
Principe de la compression:
- On divise l'image en bloc de 8*8 ou 16*16
pixels.
- On convertit pour chaque bloc le codage RVB en
codage TSL (teinte, saturation, luminance); le passage entre les
deux codages se fait grâce à des formules simples.
- On obtient ainsi une matrice où nous
appliquons une Transformée Cosinus Discrète (formule
complexe) à celle-ci. Ainsi, au lieu de laisser une valeur
pour chaque pixel, elle permet de représenter les valeurs des
pixels en fréquences qui représentent les variations des
valeurs
- Puis la matrice DTC est quantifiée c'est
à dire qu'on simplfie les valeurs: un 2 ou 3 ou -5 ...
donnerons un 0. Ces valeurs zéro prendront peu d'espace de
stockage lors de l'enregistrement du dossier. Le niveau de
compression est exprimée au moment de la quantification par
"le pas de quantification", le pas est généralement entre
1 et 25, où 1 donne la meilleure qualité d'image et 25
plus mauvaise qualité acceptable.
-Pour le codage, on lit les blocs en zig-zag afin
de grouper les valeurs nulles. On applique au résultat une
compression RLC (Run Length Coding) et un codage VLC (Variable
Length Coding), puis un algorithme Huffman ou arithmétique ou
encore Shannon- Fano pour pouvoir retrouver le codage en RVB et
pouvoir visualiser l'image.